The Modern House
The Modern House is a niche real estate agent that lists only architecturally unique homes for sale. The listings are tastefully presented with professional photos and introduction into the architecture history of the building.
Webscraping The Modern House website using Selenium & Beautiful Soup
The Modern House website has a listing of all their houses on sale now. The problem with scraping through html is that the website is dynamic. You have to scroll down to reveal all the listings.
This is where I would use Selenium to automate this process of scrolling.
# Webscraping tools
from urllib.request import urlopen
from bs4 import BeautifulSoup
from selenium import webdriver
# Utilities
import os
# Data analysis
import pandas as pd
import numpy as np
# Webscraping url - The Modern House
## Build a function to scroll down the pages to the end and extract page source using Chrome
def scrollExtractChrome(url):
# Using the chrome driver
chrome_path = os.getcwd() + '/chromedriver'
browser = webdriver.Chrome(chrome_path)
# Tell Selenium to get the URL you're interested in.
browser.get(url)
# Selenium script to scroll to the bottom, wait 3 seconds for the next batch of data to load, then continue scrolling. It will continue to do this until the page stops loading new data.
lenOfPage = browser.execute_script("window.scrollTo(0, document.body.scrollHeight);var lenOfPage=document.body.scrollHeight;return lenOfPage;")
match=False
while(match==False):
lastCount = lenOfPage
time.sleep(3)
lenOfPage = browser.execute_script("window.scrollTo(0, document.body.scrollHeight);var lenOfPage=document.body.scrollHeight;return lenOfPage;")
if lastCount==lenOfPage:
match=True
# Now that the page is fully scrolled, grab the source code.
return browser.page_source
## Define a function to extract data from the page source using a specific regex pattern
def extractFromXML(page,tag,tag_class,pattern):
#Create BeautifulSoup object
soup = BeautifulSoup(page,'lxml')
#Filter all the entries
rows= soup.find_all(tag,attrs={'class':tag_class})
#Use the regex pattern to extract data needed
attributes=[re.findall(pattern, i.prettify()) for i in rows]
#Flatten out row list for easy import into pandas
return [item for sublist in attributes for item in sublist]
# Define parameters for the functions made above
url = "https://www.themodernhouse.com/sales-list/homes/all/"
pattern_location = "\\n\s+(?P.*)\\n\s+
\\n\s+(?P.*)\\n
\\n"
pattern_price = "\\n\s+(?P£.*)\\n\s+
\\n\s+(?P.*)\\n "
# Compile all the information downloaded into a dataframe
df = pd.DataFrame()
for i in range(1,6):
link = url + str(i)
#Extract data using the defined functions:
page = scrollExtractChrome(link)
location_extract = extractFromXML(page,'h3', 'listing-name', pattern_location)
price_extract = extractFromXML(page,'div', 'listing-price', pattern_price)
#Join two datasets together and import to pandas
data = [a+b for a,b in zip(location_extract,price_extract)]
labels = ['address','postcode','price','hold']
df_part = pd.DataFrame.from_records(data, columns=labels)
df_part['bedrooms'] = i
df = df.append(df_part)
df = df.reset_index(drop=True)
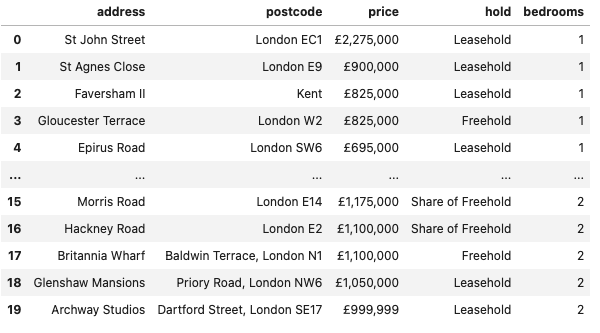
df.head(20)
The first step is to define a scrolling function scrollExtractChrome where it uses a chrome driver (to download) in your folder to execute some javascript. The script I used here is basically asking the browser to scroll down to reveal a new page until the page count doesn't increase anymore.
Once the scrolling is complete, the next step is to define a function extractFromXML to extract the data we need from the html code underneath the website. I used some Beautiful Soup functions to help me get to the right tags underlying. To find the right tags, you can right click Inspect and point to the element in the page to get the location of the html tags in the page.
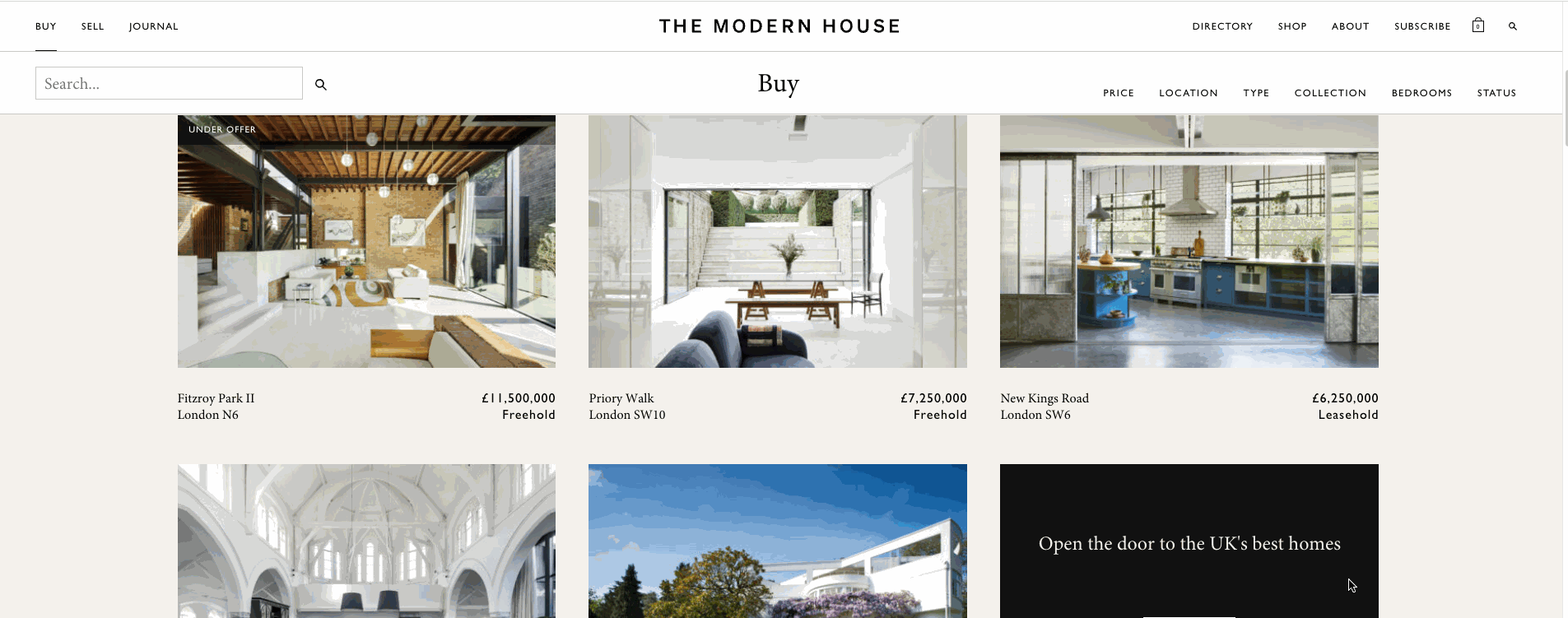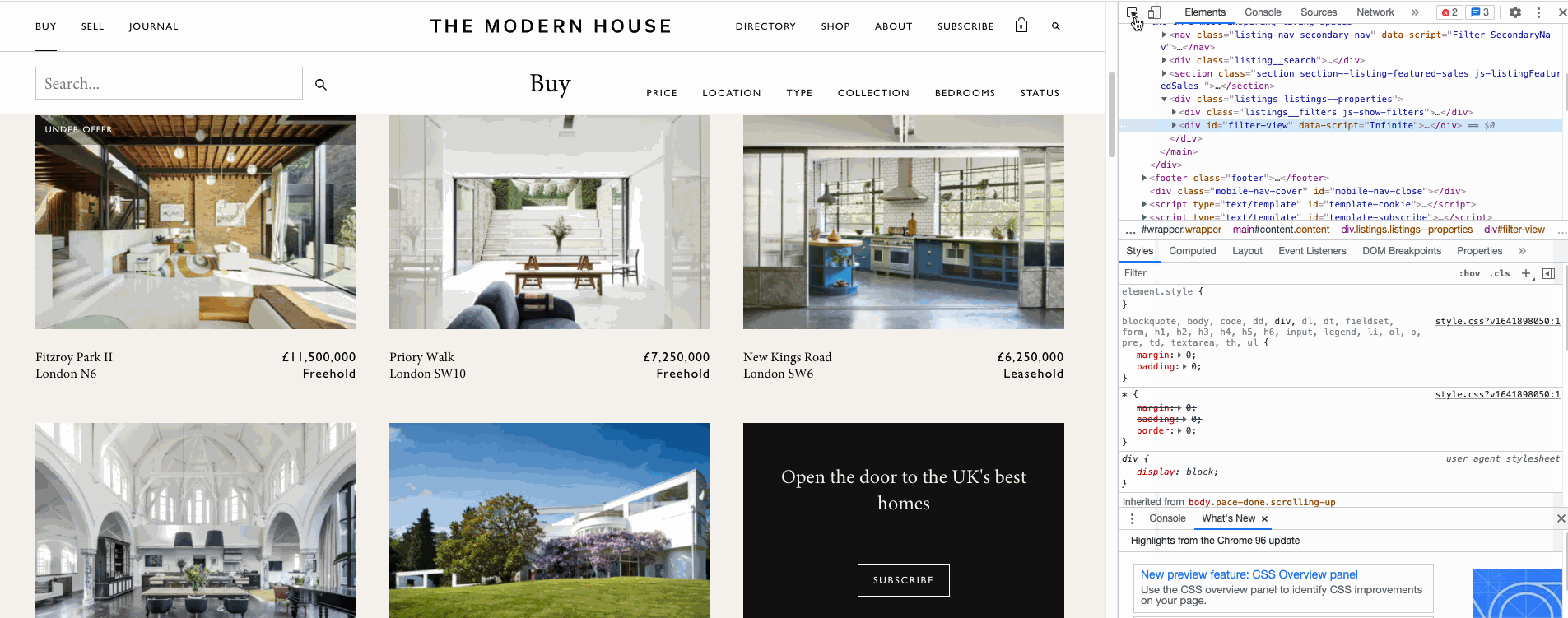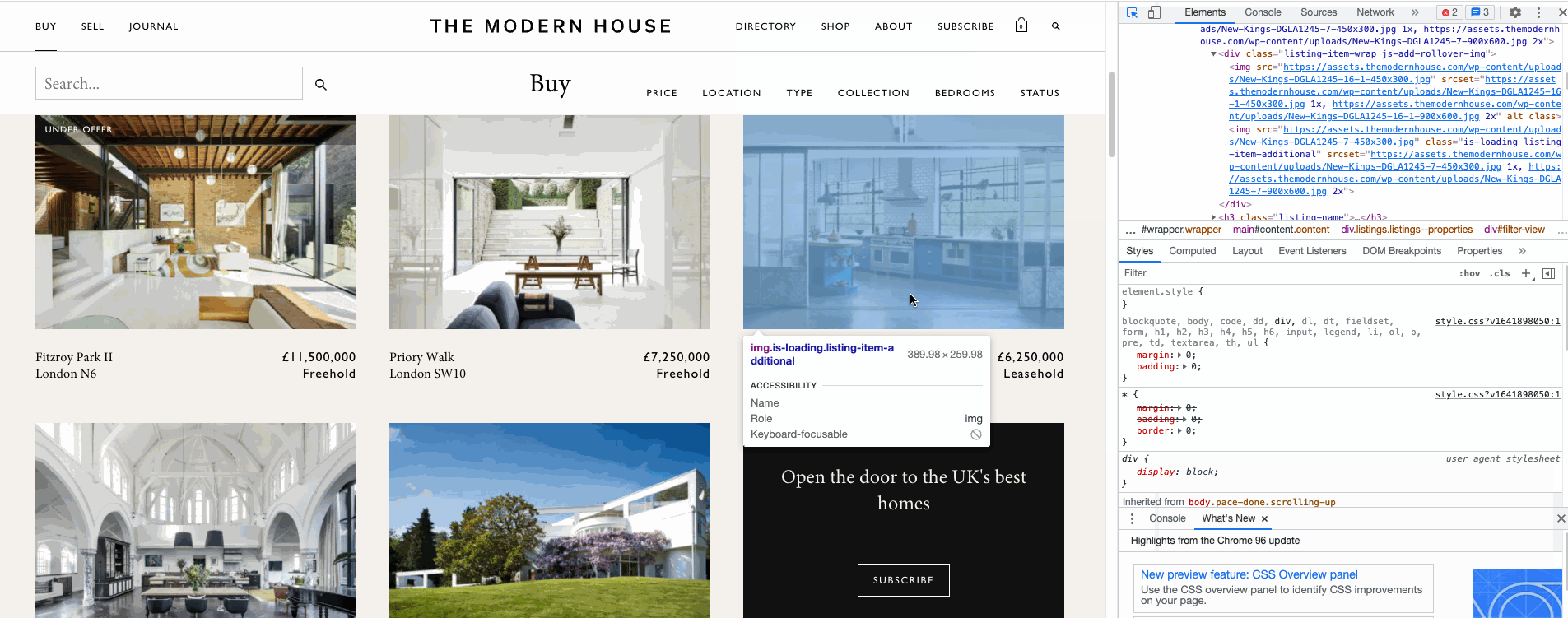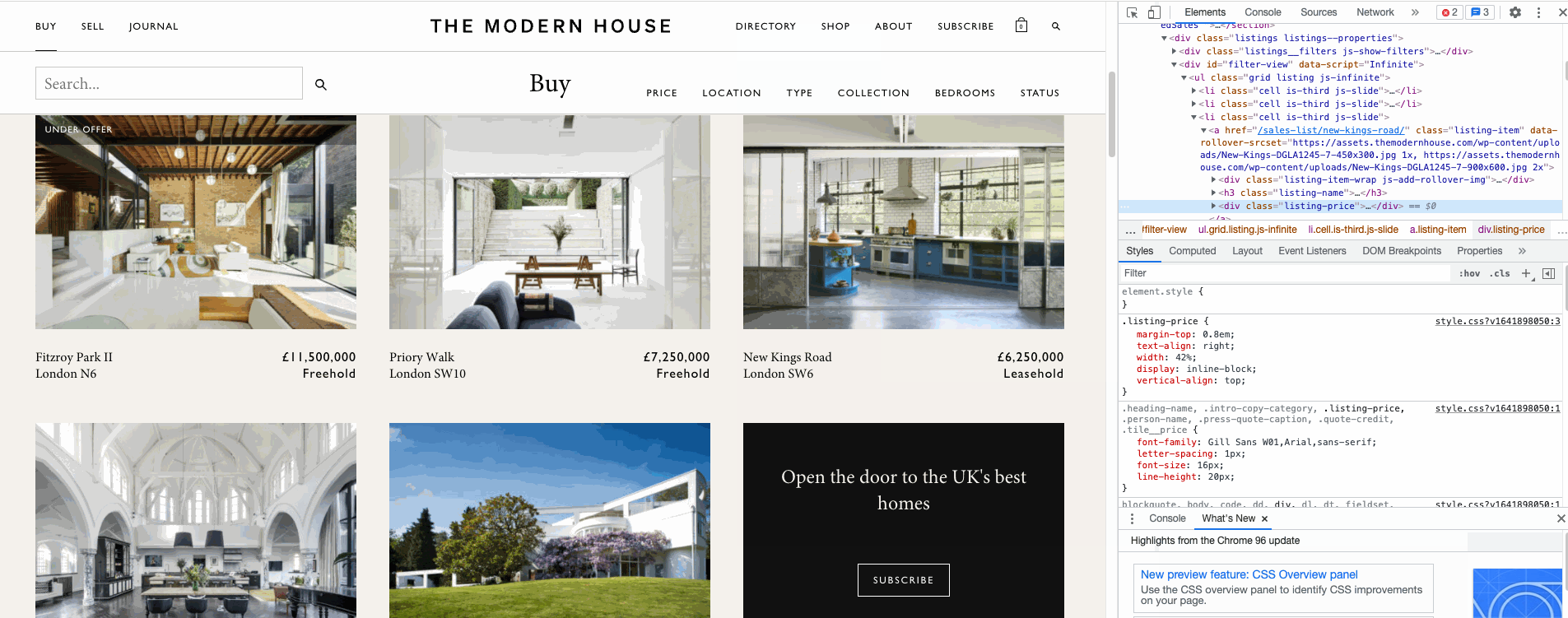
Finally, after collecting all the data in a list, I append them together into a Pandas Dataframe like the one shown below.
Personally, I was interested in whether Modern House was able to achieve a premium over other real estate agencies. I did an analysis using data from Zoopla to compare prices achieved on Modern House versus prices achieved on Zoopla for neighbouring flats. You can read about it on my github.